英语
matplotlib
sqlserver
vga
lua 元表
lua metatable
PMP
球形消息传递
Exception
微机原理
mysql存储过程
分级存储
如何修复网站漏洞
界面设计
Pascal
YOLOX
太空工程师
u-boot
运动场地预约
工业智能网关
pyspark
2024/4/11 19:51:05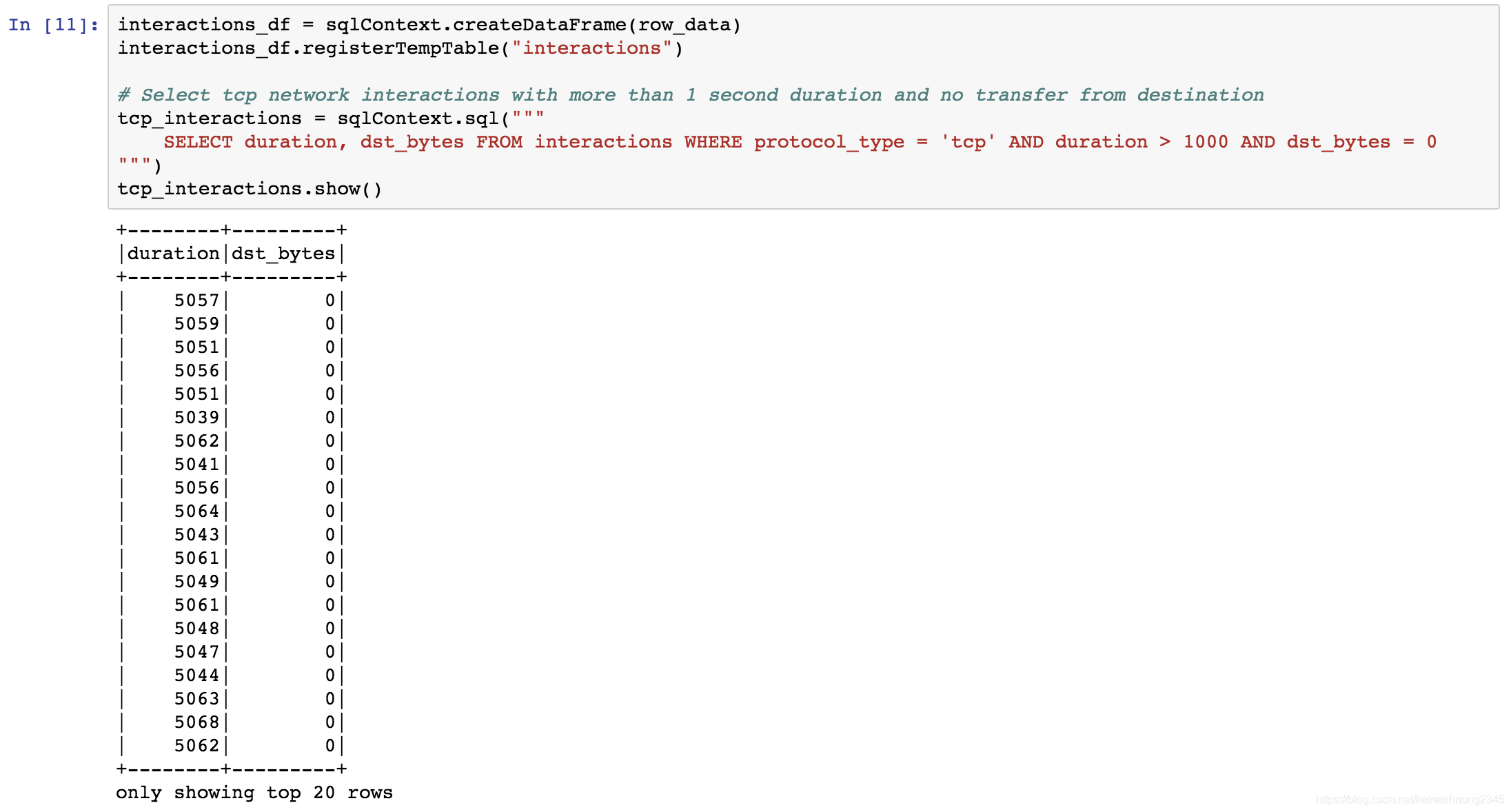
如何在30秒內建構Spark環境--使用docker-compose 踩坑實錄
如何在30秒內建構PySparkJupyter環境--使用docker-compose 踩坑實錄前言使用步驟1. 下載這個項目2. 進入項目的根目錄3. 創造並運行PySparkJupyter的容器4. 查看MasterWebUI和WorkerWebUI5. 在瀏覽器中開啟Jupyter Notebook6. 運行spark-example.ipynbDockerfile內容介紹踩坑實…

使用docker stack建構跨主機PySpark+Jupyter集群
使用docker stack建構跨主機PySparkJupyter集群前言使用步驟1. 下載這個項目2. 建立docker swarm3. 啟動docker集群4. 在命令行中監控docker集群5. 在瀏覽器中監控docker集群與原版的差異原來的docker-compose.yml修改過後的docker-compose-visualizer.ymlvisualizerportsvolum…

(一)PySpark3:安装教程及RDD编程(非常详细)
目录
一、pyspark介绍
二、PySpark安装
三、RDD编程
1、创建RDD
2、常用Action操作
①collect
②take
③takeSample
④first
⑤count
⑥reduce
⑦foreach
⑧countByKey
⑨saveAsTextFile
3、常用Transformation操作
①map
②filter
③flatMap
④sample
⑤d…
python, pyspark导入自定义包
python导入自定义包
在python中,py文件是一个模块,可以import导入。
如果想导入一系列功能的多个py文件,可以把这些文件放入一个包里,这个包里需要一个__init__.py文件。init.py的作用就是把文件夹变成一个python模块。
情况1&…
pycharm pyspark连接虚拟机的hive表 读取数据
方法:
hive配置hiveserver2和metastore url
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop111</value>
</property><!-- 指定hiveserver2连接的端口号 -…

13-pyspark的共享变量用法总结
目录 前言广播变量广播变量的作用 广播变量的使用方式 累加器累加器的作用累加器的优缺点累加器的使用方式 PySpark实战笔记系列第四篇
10-用PySpark建立第一个Spark RDD(PySpark实战笔记系列第一篇)11-pyspark的RDD的变换与动作算子总结(PySpark实战笔记系列第二篇))12-pysp…

Pyspark学习笔记小总
pyspark官方文档: https://spark.apache.org/docs/latest/api/python/index.html pyspark案例教程: https://sparkbyexamples.com/pyspark-tutorial/
1. 写在前面
这篇文章记录下最近学习的有关Pyspark以及用spark sql去处理大规模数据的一些常用语法,之前总觉得p…
PySpark简明教程 02 pyspark实战 入门例子
一个简单的例子带你进入pyspark的大门,对!我们的入门程序不是wordcount,也不是hello world。我们不一样、不一样。
目标:找到股息率大于3%的行业,将结果输出到指定目录。
1 实验文件
文件为深圳股市的股息率统计(截…
(四)PySpark3:Mlib机器学习实战-信用卡交易数据异常检测
目录
一、Spark Mlib
二、案例背景以及数据集
三、代码
四、总结 PySpark系列文章:
(一)PySpark3:安装教程及RDD编程
(二)PySpark3:SparkSQL编程
(三)PySpark3&am…
12-pyspark的RDD算子注意事项总结
目录 相近算子异同总结相近变换算子异同foreach和foreachPartitionfold和reducecoalesce和repatition 相近动作算子异同cache和persist 算子注意事项需要注意的变换算子需要注意的动作算子 PySpark实战笔记系列第三篇
10-用PySpark建立第一个Spark RDD(PySpark实战笔记系列第…

《PySpark大数据分析实战》-16.云服务模式Databricks介绍运行案例
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
pyspark-UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters...
公司的测试环境无法打印中文,根据报错信息找了好多解决方案都没成功。历尽千辛万苦,终于有一个能成功了。
import sys
import codecssys.stdout codecs.getwriter("utf-8")(sys.stdout.detach())
print("中文")原文链接
python3报…

11-pyspark的RDD的变换与动作算子总结
目录 前言 变换算子动作算子 前言 一般来说,RDD包括两个操作算子: 变换(Transformations):变换算子的特点是懒执行,变换操作并不会立刻执行,而是需要等到有动作(Actions)…
PySpark简明教程 01专栏简介
目录
原则和风格
教程的目的
本教程的优势
内容设置 简介
简明:意思是简单而明了。 PySpark:就是用Python这门语言工具去驾驭Spark这个大数据计算引擎。
原则和风格
就是简单直接、不拖泥带水,符合开发者审美和工作需要。 所以&#x…
pyspark读写mongo的技巧和坑
技巧
每次把数据写入mongo,mongo都会自动创建_id字段,mongo中_id字段是唯一的,mongo会为这个字段自动建立索引。 写mongo之前可以指定_id的值,这样当你的写入mode是Append的时候,你的记录写入mongo,如果不…

【头歌实训】PySpark Streaming 入门
文章目录 第1关:SparkStreaming 基础 与 套接字流任务描述相关知识Spark Streaming 简介Python 与 Spark StreamingPython Spark Streaming APISpark Streaming 初体验(套接字流) 编程要求测试说明答案代码 第2关:文件流任务描述相…
pyspark读写mongo数据库
读写mongo
方式一
from pyspark.sql import SparkSession
my_spark SparkSession \.builder \.appName("myApp") \.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/test.coll") \.config("spark.mongodb.output.uri", &q…
pyspark-用户自定义函数udf
在PySpark中,你用python语法建立一个函数,然后用PySpark SQL中的udf()方法在dataframe中使用,或将其注册成udf并在sql中使用。
例1 通过select()使用UDF
from pyspark.sql.functions import col, udf
from pyspark.sql.types import String…
pyspark写入elasticsearch及注意点
1 dataframe写入es es_url: ip地址
es_port:端口
es_user:用户名
es_pass:密码
sparkSparkSession.builder\.config("spark.es.nodes",es_url)\.config("spark.es.port",es_port)\.config("es.net.http.auth.user&q…
(二)PySpark3:SparkSQL编程
目录
一、SparkSQL介绍
二、创建DataFrame
1、通过ToDF方法
2、通过createDataFrame方法
3、通过读取文件或数据库
三、保存DataFrame
四、DataFrame API
1、显示数据
2、统计信息
3、类RDD操作
4、类Excel操作
5、类SQL表操作
五、DataFrameSQL
1、注册视图
2、…
pyspark打包依赖包使用python虚拟环境
一、anaconda创建python环境
anaconda创建python环境
在这篇博客中,已经很清楚地描述了如何通过anaconda来创建你需要的python环境:即合适的python版本和包含你需要的依赖包。
二、打包python环境
假设我们的python环境名称为py_env,那么…
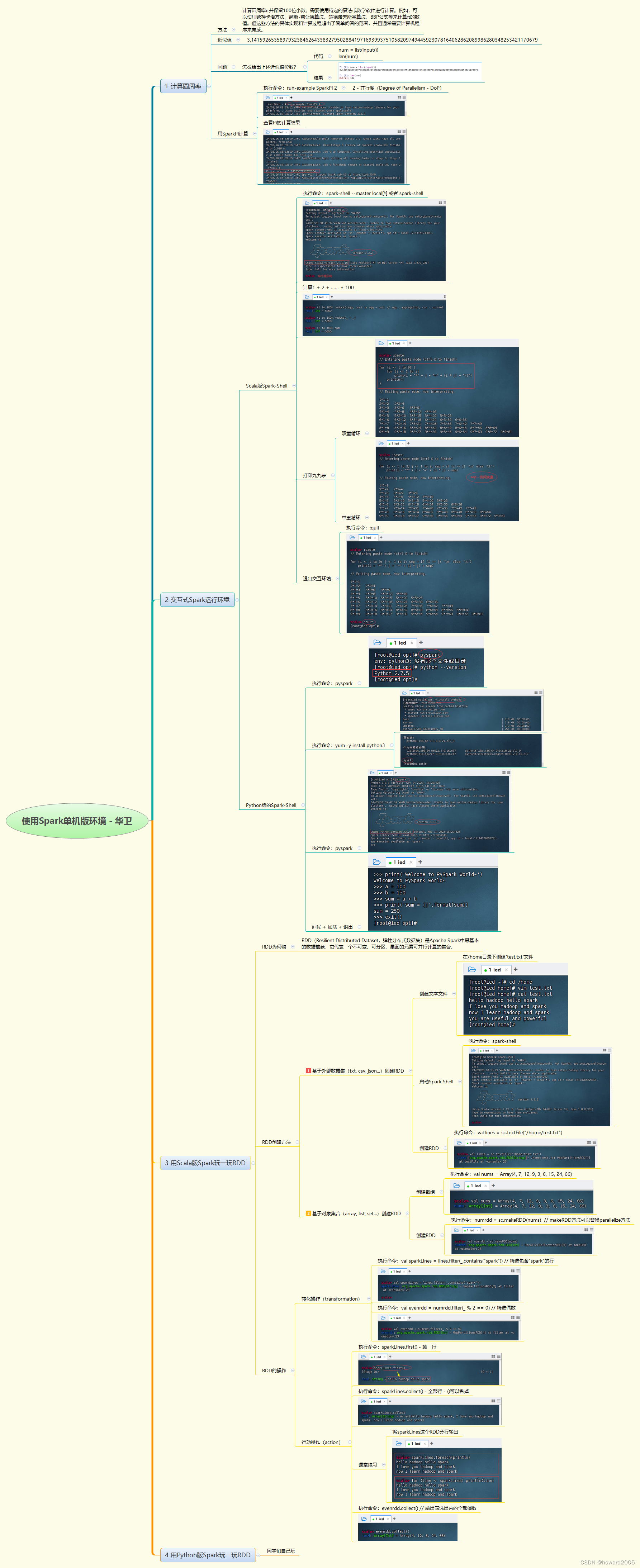
使用Spark单机版环境
在Spark单机版环境中,可通过多种方式进行实战操作。首先,可使用特定算法或数学软件计算圆周率π,并通过SparkPi工具验证结果。其次,在交互式Scala版或Python版Spark Shell中,可以进行简单的计算、打印九九表等操作&…

《PySpark大数据分析实战》-18.什么是数据分析
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
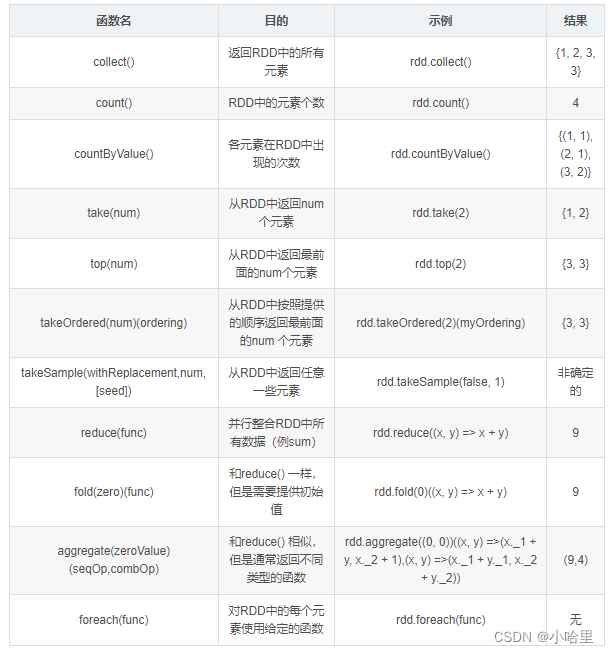
Spark RDD | 常用函数讲解与代码实践
😄 因为spark里用的就是RDD数据结构来存储数据,所以对数据处理离不开RDD的各种函数操作咯!这一节就跟着梁云大佬打卡下如何处理RDD。【下面章节有🔥的是用的比较多的函数】 文章目录 0、初始化pyspark环境与driver介绍0.1、初始化…
【数据开发】pyspark入门与RDD编程
【数据开发】pyspark入门与RDD编程 文章目录 1、pyspark介绍2、RDD与基础概念3、RDD编程3.1 Transformation/Action3.2 数据开发流程与环节 1、pyspark介绍
pyspark的用途
机器学习专有的数据分析。数据科学使用Python和支持性库的大数据。
spark与pyspark的关系
spark是一…
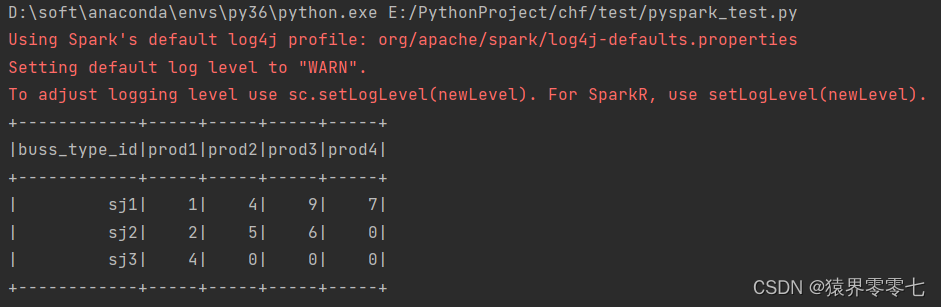
pyspark连接mysql数据库报错
使用pyspark连接mysql数据库代码如下
spark_conf SparkConf().setAppName("MyApp").setMaster("local")spark SparkSession.builder.config(confspark_conf).getOrCreate()url "jdbc:mysql://localhost:3306/test?useUnicodetrue&characterE…
Python基础练习案例
Python基础练习案例 一、Python基础语法1、练习案例1:求钱包余额2、练习案例2:股价计算小程序3、练习案例3:欢迎登陆小程序 二、Python判断语句1、练习案例1:成年人判断2、练习案例2:我要买票吗3、练习案例3࿱…

《PySpark大数据分析实战》-14.云服务模式Databricks介绍基本概念
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
pyspark读取数据库性能优化
当数据量很大时,读取方式
dbtable写sql语句
dbtable和query配置不能同时存在,选一种即可。里面都可以直接写sql语句
jdbcDF spark.read.format("jdbc")\.option("driver",driver)\.option("url",url)\.option("d…

Python大数据处理利器之Pyspark详解
摘要:
在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark…
《PySpark大数据分析实战》-06.安装环境准备
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-25.数据可视化图表Matplotlib介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
pyspark更改列顺序存入iceberg数据库
创建环境,指定catalog
def get_spark():os.environ.setdefault(HADOOP_USER_NAME, root)# total size of serialized results of tasks is bigger than spark.driver.maxResultSize# ERROR DataWritingSparkTask: Aborting commit for partition 2 (task 2, atte…

PySpark大数据处理详细教程
欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们…
PySpark简明教程 04 Spark加载csv文件parquet文件等数据源
1 加载有固定分隔符的文件
这里有固定分隔符文件可以理解为类似CSV这样的文件,例如:每行列数相同,每列以逗号、\t、\001等固定分隔符划分的文件。主要以csv文件为例,特殊分隔符参见第1.3节
1.1 加载无header的固定分隔符文件
>>>df=spark.read.format("cs…
pyspark join用法总结
文章目录DSL(Domain-Specific Language)形式inner, full, left, right, left semi, left anti, self join多表join关联条件多个的joinsql形式参考文献DSL(Domain-Specific Language)形式
join(self, other, onNone, howNone)join() operation takes parameters as below and r…

《PySpark大数据分析实战》-15.云服务模式Databricks介绍创建集群
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-04.了解Spark
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-26.数据可视化图表Seaborn介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
sparksql中json处理
get_json_object:从json中提取出字段
SELECT get_json_object({"a":"b","c":"d"}, $.a);# 提取到了bxx表里biz_data字段存的是json格式,里面有字段aa,bb,cc
spark.sql("select get_json_object(biz_dat…
pyspark读写mysql和oracle
读写数据库一开始我使用的是方式三,后来感觉代码太长满足不了我强迫症的需求,现在有了方式一,勉强行吧。
mysql和oracle写法的格式一样。
数据库配置
user,password,driverxxx,yyy,zzz
url jdbc:mysql://host:port/database
prop {user:…
Spark自定义UDF 自定义函数
目录 注册一个UDF
你也可以指定返回类型
PySpark SQL Types类型
在Spark SQL中使用UDF
在DataFrame里使用UDF
pyspark根据正则表达式选择列
python正则表达式见python正则表达式入门
pyspark.sql.DataFrame.colRegex方法可以根据正则表达式选择列。
例1:选择所有BASE_开头的列
df.select(df.colRegex("(BASE_).")).show()()表示组,’‘表示前面的表达式出现一次或以上,…
pyspark数据类型转换-withColumn,select,selectExpr,sql四种方式
pyspark中数据类型转换共有4种方式:withColumn, select, selectExpr,sql
介绍以上方法前,我们要知道dataframe中共有哪些数据类型。每一个类型必须是DataType类的子类,包括
ArrayType, BinaryType, BooleanType, CalendarIntervalType, Dat…
PySpark 概述
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…
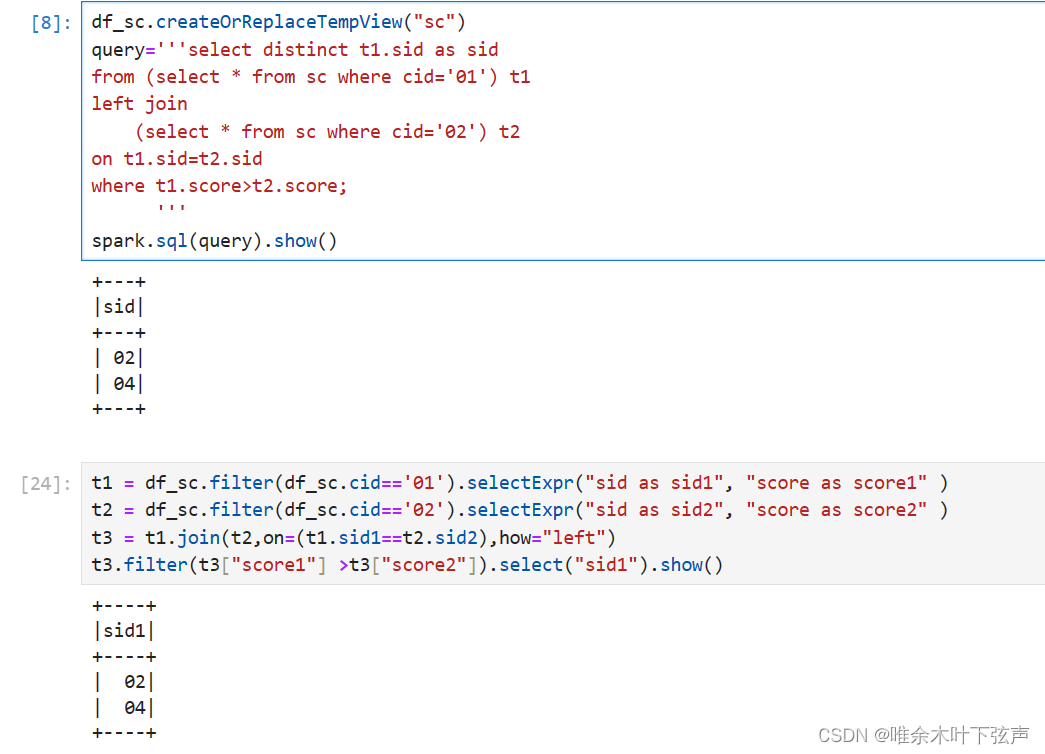
(三)PySpark3:SparkSQL40题
目录 一、前言
二、实践
三、总结 PySpark系列文章:
(一)PySpark3:安装教程及RDD编程
(二)PySpark3:SparkSQL编程
(三)PySpark3:SparkSQL40题
一、前言…

《PySpark大数据分析实战》-07.Spark本地模式安装
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
PySpark 优雅的解决依赖包管理
背景
平台所有的Spark任务都是采用Spark on yarn cluster的模式进行任务提交的,driver和executor随机分配在集群的各个节点,pySpark 由于python语言的性质,所以pySpark项目的依赖注定不能像java/scala项目那样把依赖打进jar包中轻松解决问题…

《PySpark大数据分析实战》-24.数据可视化图表介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
使用 Docker 设置 PySpark Notebook
使用 Docker 设置 PySpark Notebook 第 1 步:拉取 Docker 镜像
首先拉取jupyter/all-spark-notebook包含 Spark 3.5.0 的镜像。
docker pull jupyter/all-spark-notebook:spark-3.5.0
第 2 步:设置您的工作区
在运行 Docker 映像之前,我们…

《PySpark大数据分析实战》-09.Spark独立集群安装
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
使用 pyspark 进行 Clustering 的简单例子 -- KMeans
K-means算法适合于简单的聚类问题,但可能不适用于复杂的聚类问题。此外,在使用K-means算法之前,需要对数据进行预处理和缩放,以避免偏差。
K-means是一种聚类算法,它将数据点分为不同的簇或组。Pyspark实现的K-means算法基本遵循以下步骤: 随机选择K个点作为初始质心。根…

PySpark中DataFrame的join操作
内容导航
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统…

《PySpark大数据分析实战》-27.数据可视化图表Pyecharts介绍
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
pyspark on yarn
背景描述
pyspark 相当于 python 版的 spark-shell,介于 scala 的诡异语法,使用 pyspark on yarn 做一些调试工作还是很方便的。
配置 获取大数据集群配置文件。如果是搭建的 CDH 或者 CDP 可以直接从管理界面下载配置文件。直接下载 hive 组件的客户端…

《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…

《PySpark大数据分析实战》-11.Spark on YARN模式安装Hadoop
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…
Spark日志清洗一般流程
spark 1.6.1 python 2.7.11 前言 整理了一下使用spark来进行日志清洗及数据处理的套路,这里以pyspark为例 pyspark的启动任务套路 对于使用spark作为查询清洗工具而言,启动spark的套路主要使用sh文件进行终端带参数启动,启动后开始调用sh传递…
DataFrame窗口函数操作
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…
使用 pyspark 进行 Classification 的简单例子
This is the second assignment for the Coursera course “Advanced Machine Learning and Signal Processing”
Just execute all cells one after the other and you are done - just note that in the last one you have to update your email address (the one you’ve u…
用通配符指定文件名集-glob
在计算机编程中,glob 模式用通配符指定文件名集。
我正在使用pyspark,我想用一种表达方式来读取文件名集合。假设目录/dir1/dir2/下有2020年和2021年全部的数据,每天的数据放在该天目录下,即2021年7月1日的数据放在20210701目录下…
Python Jupyter Notebook 中的错误异常与代码调试
Python Jupyter Notebook 中的错误异常与代码调试
首先我们定义两个函数,以便够造成一些错误和异常,方便来进行对于 Jupyter Notebook 的错误异常相关知识的学习:
In [1]:
def func1(a, b):return a / bdef func2(x):a xb x - 1return f…